

The New JPA 2.0 Implementation, +15x Faster Than The Leading JPA Provider!
I loved the JPA 1.0 back in early 2000s. I started using it together with EJB 3.0 even before the stable releases. I loved it so much that I contributed bits and parts for JBoss 3.x implementations.
Those were the days our company was considerably still small in size. Creating new features and applications were more priority than the performance, because there were a lot of ideas that we have and we needed to develop and market those as fast as we can. Now, we no longer needed to write tedious and error prone xml descriptions for the data model and deployment descriptors. Nor we needed to use the curse called “XDoclet”.
On the other side, our company grew steadily, our web site has become the top portal in the country for live events and ticketing. We now had the performance problems! Although the company grew considerably, due to the economics in the industry, we did not make a lot of money. The challenge we had was our company was a ticketing company. Every e-commerce business has high and low seasons. But for ticketing there is low seasons and high hours. While you sell avarage x tickets an hour, when a blockbuster event goes on sale suddenly demand becomes 1000s of xs for an hour. Welcome to hell!
We worked day and night to tweak and enhance the application to use whatever available to keep it up on a big day. To be frank there was always a bigger event that was capable of bringing the site down no matter how hard we tried.
The dream was over, I came to realize that developing applications on top of frameworks is a bit “be careful!” along with “fun”.
I Kept Learning
I loved programming, I loved Java, I loved opensource. I developed almost every possible type applications on every possible platform I could. For the rest I went in and discovered stuff. I learned a lot from masters thanks to open source. In contrast to most, I read articles and codes written by great programmers like Linus Torvalds, Gavin King, Ed Merks and so many others.
With the experiences I gathered, I quit the ticketing company I loved and became a Software Consultant. This opened a new era in front of me that there were a lot of industries and a lot of different platforms and industries.
I am now the performance freak!
I Took The Red Pill!
One day I said to myself, could JPA be faster? If yes, how fast can it be. I spent about two weeks to create an entitymanager that persisted and loaded entities. Then I ran it and compared the results to ones off of Hibernate. The results were not really promising I was only about %50 faster than Hibernate in persisting and finding the entities. I spent another week to tweak the loops, cached metamodel chunks, changed access to classes from interfaces to abstract classes, modified the lists to arrays and so many other things. Suddenly I had a prototype that were 50+ times faster than Hibernate!
Development of Batoo JPA
I was astonished by how drastically performance went up by just paying attention to performance centric coding. By then I was using Visual VM to measure the times spent in the JPA layer. I got down and wrote a self profiling tool that measured the CPU resources spent at the JPA Layer and started implementing every aspect of the JPA 2.0 Specification. After each iteration I re-run the benchmark and when the performance dropped considerably I went back to changes and inspected the new code line by line - the profiling tool I created reported performance hit of every line of the JPA Stack.
It took about 6 months to implement the specification as a whole, on top of it, I introduced a Maven Plugin to create bytecode instrumentation at build time and a complementary Eclipse Plugin to allow use of instrumentation in Eclipse IDE.
After a carriage of 6 months Batoo JPA was born in August 2012. it measured over 15 times faster than Hibernate.
Benchmark
As stated earlier, a benchmark was introduced to measure every micro development iteration of Batoo JPA. This benchmark was not created to put forward the areas Batoo JPA was fast so that other would believe in Batoo JPA, but was created to put together a most common domain model and persistence operations that existed in almost every JPA application - so that I knew how fast Batoo JPA was.
Performance Metrics
The scenario is:
- A Person object
- With phonenumbers - PhoneNumber object
- With addresses - Address object
- That point to country - Country Object
Common life-cycle tasks has been introduced:
- Persist 100K person objects with two phone numbers and two addresses in lots of 10 per session
- Locate and load 250K person objects with lots of 10 per session
- Remove 5K person objects with lots of 5 per session
- Update 100K person objects with lots of 100
- Query person objects 25K times using Object Oriented Criteria Querying API.
- Query person objects 25K times using JPQL - Java Persistence Query Language, an SQL-like query scripting language.
For the sake of simplicity, the benchmark was run on top of in-memory embedded Derby with the profiler slicing the times spent at the
- Unit Test Layer
- JPA Layer
- Derby Layer
The times spent at the Unit Test Layer is omitted from the Results due to irrelevancy.
Results
The times given in the below tables are in milliseconds spent in the JPA layer while running the benchmark scenario. The same tests are run for Batoo and Hibernate JPA in different runs to isolate boot, memory, cache, garbage collection etc. effects.
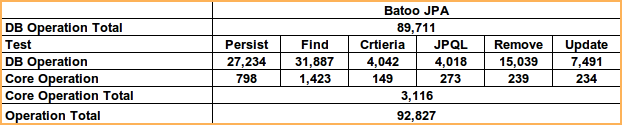
The tables below show
- the total time spent at Derby Layer as DB Operation Total
- the type of the test as Test
- the times for each test at Derby Layer as DB Operation
- the times for each test at JPA Layer as Core Operation
- the total time spent at JPA Layer as Core Operation Total
- the total time spent at both JPA and Derby Layers as Operation Total
.png)
Below are the ratios of CPU resources spent by Hibernate and Batoo JPA. It is assumed that an an application generates average 1 save, 5 locate, 2 remove and 3 update and 5 + 5 total of ten queries in ratios. Now although these numbers are extremely dependent on the application nature, some sort of assumption is needed to measure the overall speed comparison.

Given the scenario above, Batoo JPA measures over 15 times faster than Hibernate - the leading JPA implementation.
As you may have noticed Batoo JPA not only performs insanely fast at the JPA Layer it also employs a number of optimizations to relieve the pressure on the database. This is why Batoo JPA measures half the time at DB Layer in comparison to the one off of Hibernate.
Interpretation of Results
We do appreciate that JPA is not the single part of an application. But we do believe that the current JPA implementation consume quite a bit of your server budget. While a typical application cluster spends CPU resources for persistence layer about %20 to %40, Batoo JPA will well be able to bring your cluster down to half of its size allowing you save a lot on licensing administration and hardware, as well as room to scale up even for non-cluster friendly applications - in my experience I saw applications running on 96 core Solaris systems simply because they are not scalable.
Conclusion
We have managed to create a JPA Product that allows you to enjoy the great features of JPA Technology but also do not require you to compromise on performance!
On top of that Batoo JPA is developed using the Apache Coding Standards and has valuable documentation within the code. The project codebase is released with LGPL license and there is absolutely no closed source part and we envision that it would be that way forever.
As stated earlier, it also has a complementary Maven and Eclipse plugin to provide instrumentation for build and development phases.
Batoo JPA deviates from the specification almost zero, making it easy for existing JPA applications be migrated to Batoo JPA, while requiring no additional learning phase to start using it.
Last but not the least, Batoo JPA not only saves you when you run your application, but also during the time you deploy your application. Batoo JPA employs parallel deployer managers to handle deployment in parallel. Considering a developer deploys the application during his / her development phase well 10x times a day if not 100, with a moderately large domain model this may take quite a bit of developers time when summed up. Although we haven’t made a concrete benchmark on deployment speed, we know that Batoo JPA deploys about 3 4 times faster than Hibernate.
We appreciate the time you spent to read this paper and would love to have us give you a free inspection of your application and demonstrate how much you can gain by simply replacing you JPA implementation.
Thank you.
Reference
The project website - http://batoo.jp/
The sources and issue management of Batoo JPA is hosted at Github - https://github.com/organizations/BatooOrg
You may discuss Batoo JPA on StackOverflow.com - http://stackoverflow.com/questions/ask?tags=batoo+jpa
I would be very interested in seeing a benchmark comparison against ObjectDb (http://www.jpab.org/ObjectDB.html)
ReplyDeleteDear Zak, thank you for comment.
ReplyDeleteI am aware of ObjectDb. But ObjectDb is not a JPA implementation nor a RDBMS. It is the combination of the two isn't it? Therefore it is not relevant to benchmark the two. JPA is based on ORM approach on top of RDBMSs. If I am mistaken and ObjectDb CAN run on RDBMSs, then I would be very much interested on such a comparison as well...
I understand where you're coming from. ObjectDB is not an option for my projects since you can't connect it to an RDBMS backend. I've spent many hours trying to get it to work with various frameworks with very little success. I only brought it up because it has some elaborate benchmarks published (http://www.jpab.org).
ReplyDeleteEither way, great job and I look forward to trying out your implementation.
Hey Zak,
DeleteGood news a new project we are planning on to create a NoSQL DB with RDBMS replication. How does that sound? Would you like to give your input on that?
Thank you...
ReplyDeleteWow what a great job on creating a JPA implementation in such a short time. I gave batoo a little test drive with a very simple "unit" test and it starts up really fast which is a good thing for "unit" testing. Unfortunately I will not be able to migrate to batoo because I really need fetch plans (now using OpenJPA) to be able to dynamically mark relations as lazy/eager based on the use case so that the data can be efficiently transferred to a remote client that has no lazy loading (desktop app). I do not consider JPQL fetch joins to be a good alternative because it mixes concerns and results in code duplication. Also it cannot use other fetch strategies than join. Do you have any plans to include fetch plans in batoo?
ReplyDeleteI also wonder if there is a good reason why all JPA implementations that I have tried (OpenJPA, EclipseLink, Hibernate), sometimes use N+1 selects, even when everything is marked eager. Why not automatically use smart joins/subselects/batch selects? N+1 selects seem to occur especially in the presence of toOne relations. Do you happen to know if this is due to technical limitations or is it often the case that N+1 selects does perform better?
Unfortunately Batoo-jpa is no exception for a simple example I created in my attempt to overcome N+1 selects in more complex graphs: consider Order *..1 Customer where both sides of the relation are eager. We wish to select from Order (btw a small bug in batoo is that it cannot parse "SELECT o FROM Order o" which is easily worked around by renaming to Orders).
All JPA implementations I tried use a separate query for selecting the Customer.orders field. Of course I understand that because both Order.customer and Customer.orders are eager, it is very well possible that a Customer has Orders that are not selected through the WHERE clause of the query on Order. However, shouldn't JPA be smart enough to use a JOIN/subselect/batch select to efficiently fetch Customer.orders for all customers?
I did find that Hibernate can do this (not sure about EclipseLink) when you annotate Customer.orders with @BatchSize or @Fetch(FetchMode.SUBSELECT). OpenJPA seems to have a similar and not well-documented @EagerFetchMode(FetchMode.PARALLEL), but in my experience it can decide to ignore this. I think @BatchSize is also very useful in use cases that do require lazy loading. Do you plan on adding such a feature?
Also feel free to answer this question on http://stackoverflow.com/questions/13400285/preventing-n1-selects-in-jpa.
Ahh, on parallel eager fetch operations, just today we were having a chat on it.
DeleteDear Henno, first of all thank you for the kudos, and that type of appreciation what really makes it pay off.
ReplyDeleteI'll try to answer one by one:
- 'Order' is a JPQL reserved word. As JPQL follows the SQL grammar, we choose not to go around that limitation. On the other hand a more precise error message and a bit of documentation wouldn't hurt. You may follow the issue here - https://github.com/BatooOrg/BatooJPA/issues/99
- A Relation can be made eager easily but not the vice verse. So for all the relations that you ever need lazy initialization mark them as LAZY. For the eager ones you may use the feature-yet-to-be-documented @FetchStrategy, it has a basic and advanced mode. Please take a look at - https://github.com/BatooOrg/BatooJPA/blob/master/batoo-annotations/src/main/java/org/batoo/jpa/annotations/FetchStrategyType.java in
- In addition to that you CAN create good Criteria / JPQL queries without much duplication and add the associations need to be fetched beforehand based on business rules. Note that Batoo JPA does NOT need OpenSessionInView approach. If you are still in the same VM, you can re-connect, populate the lazy bit and close the connection all behind the scenes and works flawlessly for associations needed at the presentation layer. I may need to check that but QueryDSL may even handle fetch plans. Again feel free to propose your approach on issue tracker.
- Another feature you might find useful is the MAX_FETCH_JOIN_DEPTH - https://github.com/BatooOrg/BatooJPA/blob/master/batoo-jpa-spi/src/main/java/org/batoo/jpa/BJPASettings.java#L100 this can be still overriden by @FetchStragegy but limits the depth globally.
- A better approach on paginated XToMany associations is underway, stay tuned, better create an issue and help us out by your field experience guidence.
On top of all, I'll take a look at your StackOverflow case and meanwhie feel free to get in touch on GTalk / Email if you need to have discussion on hceylan DOT batoo DOR org address.